글을 불러오는 중…
Post
추적과 검증이 안 되는 스킬은 죽은 스킬이다 — 이미 푼 문제로 다시 풀어보기
Claude Code 스킬을 만들면 끝일까? 만든 사람 머릿속에 있는 절차가 SKILL.md로 옮겨졌는지, 새로 들어온 세션이 같은 절차를 따라가는지는 별개의 문제다. 이미 한번 해결해 본 사건을 새 워크트리에서 스킬로 다시 풀어보고, 산출물을 비교한다 — 그게 검증이다.
추적과 검증이 안 되는 스킬은 죽은 스킬이다.
지난 글에서는 사내 AI 상담봇 사건 디버깅 절차를 Claude Code 스킬로 만든 이야기를 썼다. 그 글은 "스킬을 어떻게 설계했나"에 대한 것이었고, 이 글은 그 다음 — "스킬이 정말로 살아 있는지 어떻게 확인했나"에 대한 것이다.
스킬이 살아 있다는 게 뭔가
스킬을 한 번 작성하고 끝내면, 그건 만든 사람의 머릿속에만 살아 있는 도구다. 다음에 같은 류의 사건이 들어왔을 때, 새 세션의 Claude Code가 SKILL.md를 읽고 같은 절차를 따라갈지, 어디서 새고 어디서 함정에 빠질지는 아무도 모른다.
스킬이 살아 있다고 말할 수 있으려면 두 가지가 필요하다.
- 산출물(artifact) 이 있어야 한다. 모든 단계의 결과물이 디스크에 남아야 한다. 추적이 가능해야 검증도 가능하다. 산출물이 없으면 스킬의 모든 과정은 블랙박스다.
- 단계(stage) 가 있어야 한다. 어디까지 가서 어디서 멈췄는지가 명확해야 다음 사람(또는 다음 세션)이 이어받거나 다시 돌릴 수 있다.
이 두 가지가 갖춰진 스킬만 검증 대상이 된다. 산출물 없는 스킬은 검증할 게 없으니 그대로 죽은 스킬이다.
검증의 절차
내가 쓰는 8단계 프로세스를 그대로 옮긴다.
- 이슈 어사인 (실제 사건이 들어옴)
- 직접 문제 해결 (스킬 없이, 머리로)
- 문제 해결 후 해당 PR / 커밋을 태깅
- 1·2 과정에서 수행한 일들 정리
- 정리한 내용을 바탕으로 에이전트에게 스킬로 만들어 달라고 요청
- 만들어진 스킬을 가지고 새로운 세션에서 3번 문제를 다시 해결 시도
- 3번과 비교해서 정상적인 해결이 될 때까지 스킬을 리팩토링
- 3번과 비슷하거나 더 나은 결과가 나오면 스킬 제작 완료
핵심은 6번이다. 스킬을 만든 그 세션·그 사람이 스킬을 검증하면 confirmation bias가 생긴다 — 스킬이 좋은 게 아니라 같은 사람이 같은 사건을 두 번 기억해서 잘 푼 것일 수도 있다. 그래서 새 워크트리에 깨끗한 세션을 띄우고, 그 세션은 SKILL.md만 읽고 사건을 처음 보는 것처럼 따라가야 한다.
실제 검증 — 이미 푼 사건을 다시 풀어보기
이 검증 프로세스를 처음 적용한 대상은, 지난 글에서 다룬 상담봇 오답 사건 중 하나였다.
대략적인 구조는 이랬다. 봇이 도메인 규칙(예: "이용일까지 N일 남았으면 수수료 X%")을 자연어로 인용하면서 N 값을 LLM이 직접 산술로 계산하게 두었다. 그 결과 한 단계 어긋난 N으로 잘못된 수수료 버킷에 매칭되어 정반대 결론을 안내. 해결은 같은 패턴의 보편적 처방이었다 — 서버에서 결정적으로 계산하고 LLM은 결과만 복창하게 만든 것.
이 사건은 이미 PR이 머지되어 production에서 끝난 상태였고, 어떤 결과물이 나와야 하는지 정답이 있었다. 검증에 딱 맞는 재료였다.
검증 setup — 스킬 실행과 모니터링을 분리한다
검증의 핵심은 두 개의 tmux 세션을 분리하는 것이다. 한 쪽에서는 문제 태깅된 워크트리에서 스킬이 돌아가고, 다른 쪽(메인)에서는 또 다른 Claude Code 인스턴스가 그 진행을 실시간으로 관찰한다.
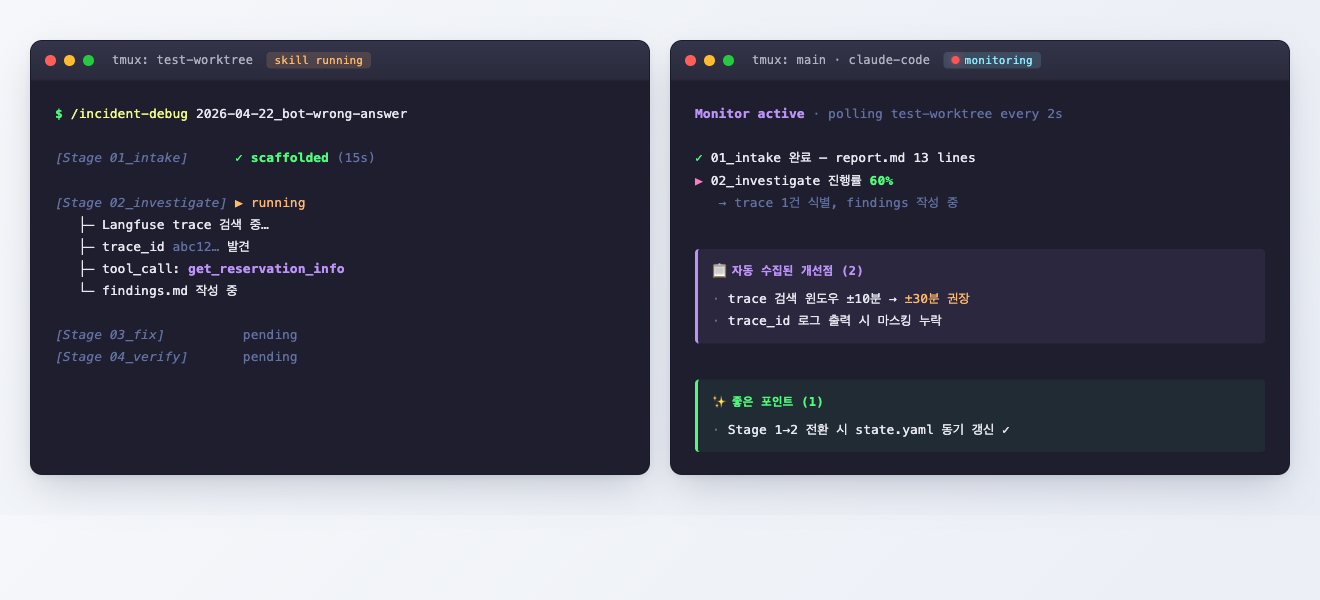
이렇게 분리하는 이유가 두 가지다.
- 스킬을 돌리는 세션은 SKILL.md만 보고 일한다 — 검증자(나) 의 컨텍스트나 힌트가 들어가지 않게.
- 모니터링 세션은 스킬을 돌리지 않고 평가만 한다 — Stage 전환·파일 생성·tool 호출 같은 신호를 폴링하면서, 개선점과 좋은 포인트를 자동으로 누적한다.
이 setup이 검증을 사람의 한 번-읽기에 의존하지 않고, 또 다른 LLM-기반 평가자에게 위임할 수 있게 만든다.
모니터가 좋은 포인트를 자동으로 검출한다
모니터 측 Claude Code는 단순히 진행 상황을 보고만 하지 않는다. SKILL.md 의 명세를 알고 있으면서, 진행 중인 스킬이 그 명세를 잘 따르고 있는 부분과 누락하거나 어긋나는 부분을 분리해서 누적한다.
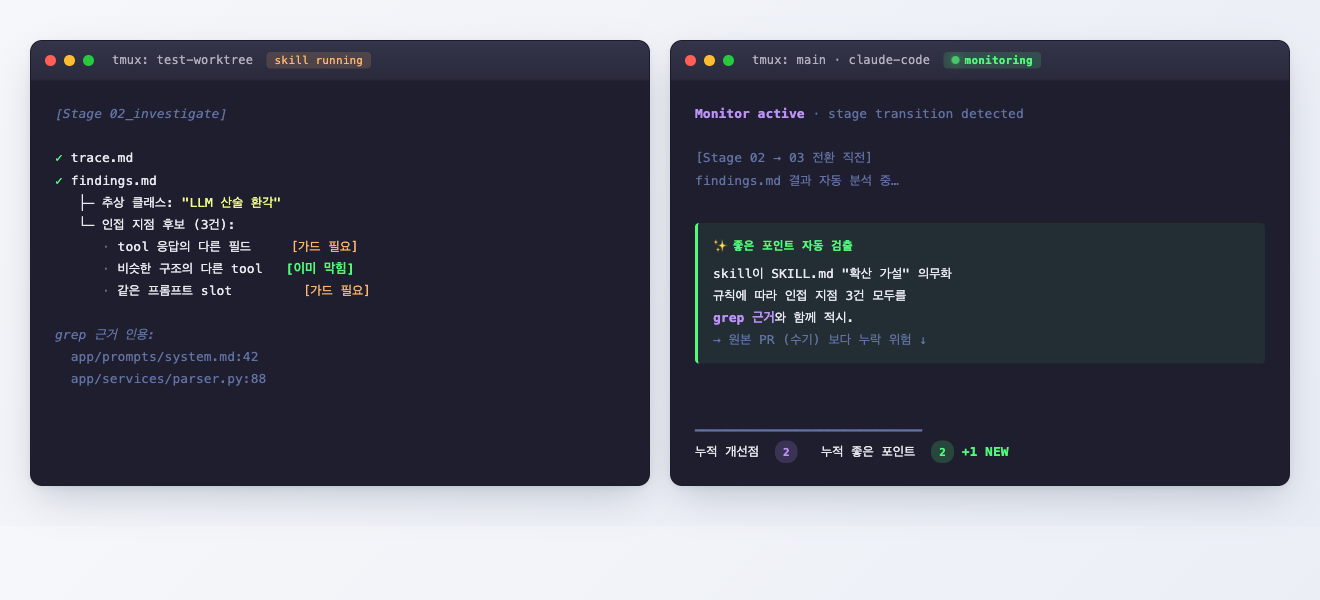
예를 들어 위 스크린샷에서 모니터는 Stage 02→03 전환 직전에 findings.md 의 결과를 읽고, "확산 가설 섹션을 grep 근거와 함께 인접 지점 3건을 모두 적시했다"는 것을 좋은 포인트로 자동 검출했다. 이건 SKILL.md 가 그 섹션을 의무화한 규칙이 실제 동작에서 반영되었음을 의미하는 신호다.
좋은 포인트가 누적되는 것도 중요하지만, 모니터 측이 누락을 잡아내는 것도 같은 무게로 중요하다. 둘 다 다음 검증 사이클에서 SKILL.md 를 어디로 보강할지의 입력이 된다.
사용자는 "왜 그랬어?" 만 묻는다 — 분석은 Claude Code가 한다
검증 세션이 멈추거나 의외의 동작을 했을 때, 사용자가 SKILL.md 를 직접 뒤져 원인을 찾는 게 아니다. 메인 Claude Code 에게 "왜 그렇게 동작했지?" 라고 묻고, Claude Code가 SKILL.md 를 읽고 grep 하고 원본 세션 로그와 diff 떠서 근본 원인을 찾는다.
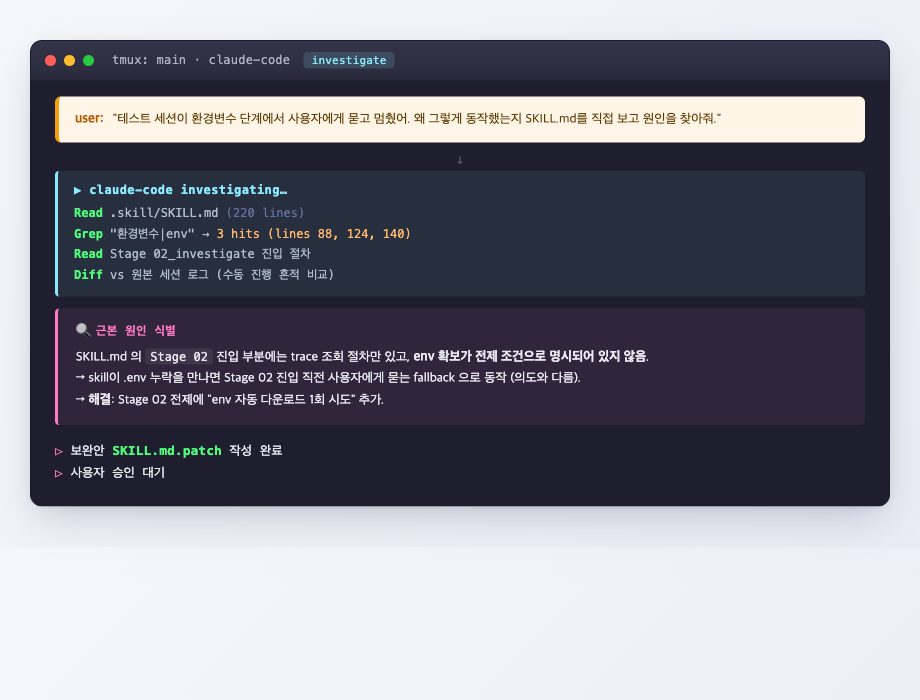
위 예시를 보면, 검증 세션이 환경변수 단계에서 사용자에게 묻고 멈췄다. 사용자가 메인에게 "왜?" 라고 묻자 Claude Code가:
- SKILL.md 220줄을 통째로 읽음
- "환경변수" 키워드로 grep — 3개 위치 발견
- Stage 02 진입 절차 부분 정독
- 원본 세션 로그와 diff 비교 (수동 진행 흔적 vs 현재 멈춤 흔적)
→ 근본 원인 식별: SKILL.md 의 Stage 02 진입 부분에 trace 조회 절차만 있고 env 확보가 전제 조건으로 명시되어 있지 않음. 그래서 skill이 .env 누락을 만나면 사용자에게 묻는 fallback 으로 동작한 것.
이 흐름의 가치는, 사용자가 매번 SKILL.md 를 다시 읽지 않아도 된다는 점이다. 사용자가 보는 건 "증상" 뿐이고, 그것을 명세 위반 또는 명세 누락으로 환원해 패치 후보를 만드는 작업은 Claude Code 가 한다. 검증의 부담이 사람 → 모델로 옮겨간다.
사이클이 끝나면 PASS / FAIL / 개선 항목 표로 정리
한 사이클이 끝나면, 모니터가 누적한 좋은 포인트·개선점들이 표로 정리된다.

세 종류의 항목이 나온다.
| 종류 | 의미 | 다음 행동 |
|---|---|---|
| PASS | 원본과 같거나 더 나은 결과 | 그대로 둔다 |
| FAIL | 원본보다 명백히 나쁜 결과 (단계 누락·잘못된 결론·산출물 부재) | SKILL.md 보완 → 다시 돌린다 |
| 개선 항목 | PASS 했지만 다음 사건에선 안 될 것 같은 부분 | SKILL.md 에 가드 추가 |
이 표를 만들어 보면 종종 "원본 PR 보다 검증 세션이 더 잘 풀었다" 항목이 나온다. 사람 머리는 잊어버리는 게 많고 단계를 건너뛰니까. 스킬은 매 단계를 강제로 거치니 일관성이 더 높을 때가 있다.
without skill vs within skill — 진짜 같은 결론에 도달했나
마지막 검증 단계는, 원래 사람 머리로 풀었던 결과(without skill) 와 검증 세션이 만든 산출물(within skill) 을 같은 축으로 나란히 놓고 비교하는 것이다.
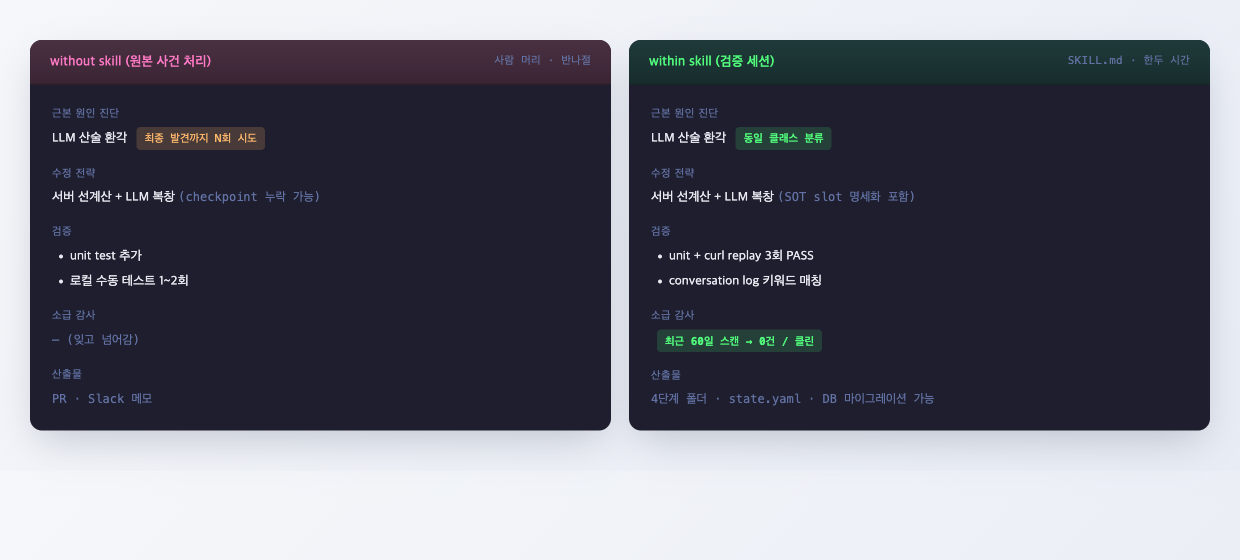
비교의 기준은 "결론이 같은가" 가 아니라 "근본 원인 진단과 수정 전략의 골격이 같은가" 다. 코드 한 줄 한 줄이 같을 필요는 없다 (리팩터링 결정 같은 건 매번 다를 수 있다). 다만 다음 세 가지는 일치해야 한다.
- 근본 원인 진단 — 같은 버그 클래스로 분류했나
- 수정 전략 — 결정적 로직 분리·서버 선계산 같은 핵심 결정이 같은 방향인가
- 검증 방법 — 같은 시나리오로 재현·확인했나
이 세 가지가 일치하면 검증 PASS. 하나라도 어긋나면 — SKILL.md 의 어느 부분이 그 결정을 충분히 안내하지 못했는지 찾아서 보완하고 다시 돌린다.
흥미로운 건 within skill 이 종종 원본보다 더 엄격하다는 점이다. 사람은 "이 정도면 됐지" 하고 소급 감사를 빼먹지만, 스킬은 4-Audit 게이트를 강제로 거친다. 사람은 unit test 한두 번으로 끝내지만, 스킬은 curl replay 3회 PASS 를 명세로 박아 둔다. 스킬은 사람의 평균이 아니라 사람의 베스트를 매번 강제하는 도구다.
검증 과정에서 발견한 함정들
이 사이클을 몇 번 돌리면서 배운 것들.
(1) 검증 세션은 사건의 정답을 미리 보여주면 안 된다. "이 사건은 이런 원인이었어" 같은 힌트를 주면 confirmation bias 가 즉시 들어온다. 검증 세션은 사건 제보 원문만 보고 출발해야 한다. 그래서 SKILL.md 자체에도 구체 incident 사례는 일부러 쓰지 않았다 (지난 글의 "의도적으로 빼놓은 것들" 섹션 참조).
(2) 한 번의 PASS 는 PASS 가 아니다. LLM 은 비결정적이다. 같은 사건을 같은 SKILL.md 로 3~5회 돌려서 모두 PASS 여야 진짜 PASS. 한 번 운이 좋아서 PASS 한 거랑 구분해야 한다.
(3) 검증 사이클이 길어지면 결국 새 사건이 들어온다. 그러면 그 사건이 곧 새 검증 케이스가 된다. 검증은 끝나지 않는다 — 그저 다음 사건을 기다리는 것뿐이다.
(4) SKILL.md 가 두꺼워지는 건 좋은 신호다. 처음에는 짧았던 SKILL.md 가 검증 사이클 몇 번을 돌고 나면 몇 배로 늘어난다. 모두 "원래 머릿속에 있었지만 명세에 없었던" 암묵지가 옮겨진 것. 명세가 두꺼워지는 만큼 다음 검증 세션은 같은 함정에 빠지지 않는다.
마무리
스킬은 코드와 같다. 코드는 회귀 테스트가 있어야 살아 있고, 스킬도 마찬가지다. 다만 LLM 기반 스킬은 unit test 로 회귀를 잡을 수 없다 — 모델이 비결정적이고, 진짜 측정해야 하는 건 "절차의 일관성" 이지 "출력의 동일성" 이 아니다.
그래서 회귀 테스트의 형태가 다르다. 이미 푼 사건을 깨끗한 새 세션에서 스킬로 다시 풀어보고, 또 다른 Claude Code 가 그 진행을 모니터링하면서 4단계 산출물이 원본과 같은 골격으로 나오는지, 좋은 포인트와 누락이 어떤 비율로 누적되는지 본다. 사람 머리로 평가하는 단계가 들어가지만, 산출물이 명시적으로 디스크에 쌓이게 만들어 둔 덕분에 모니터 측 모델이 그 평가의 1차 분석까지 수행할 수 있다. 산출물이 없는 블랙박스 스킬은 원천적으로 이 회귀 테스트를 돌릴 수 없다.
스킬을 만들려고 한다면, 검증 가능성을 처음부터 설계에 박아 두는 것을 강력히 권한다. 단계마다 산출물을 강제하고, 그 산출물의 포맷을 일관되게 정해 두면, 다음에 사건이 들어올 때 "스킬이 살아 있는지" 를 바로 확인할 수 있다.
추적과 검증이 안 되는 스킬은 죽은 스킬이다. 그 명제를 거꾸로 뒤집으면, 추적과 검증이 가능한 스킬만 살아 있다.