글을 불러오는 중…
Post
AI 상담봇 사건 대응을 Claude Code 스킬로 만든 이야기
사내 AI 상담봇에서 "이 예약에 대해 봇이 틀린 답을 했다"는 제보가 반복됐다. 매번 LLM trace · Cloud Run 로그 · 코드를 같은 패턴으로 뒤지다가, 그 절차 자체를 Claude Code skill로 만들었다. 4단계(intake → investigate → fix → verify) 구조와 그 안에 박힌 설계 결정들에 대한 이야기.
같은 형태의 사건이 반복된다
사내 AI 상담봇을 운영하다 보면, 상담사로부터 같은 형태의 제보가 주기적으로 들어온다.
"이 예약에 대해 봇이 환불 수수료를 잘못 안내했어요" "고객이 이 메시지를 보냈는데 봇이 엉뚱한 답을 했어요" "봇이 이용일을 헷갈렸나봐요"
증상은 매번 다르지만, 디버깅 절차는 거의 항상 동일했다.
- 제보에서 "어느 대화"인지 찾는다 → 보통 상담사는 사건 시각·발화 조각만 알고 내부 식별자(주문번호·세션ID)는 모른다.
- LLM 관찰 플랫폼에서 그 trace를 찾는다 → 발화 조각으로 키워드 검색.
- trace의 tool 호출 입력·출력을 본다 → 외부 API가 잘못된 데이터를 줬는지, LLM이 환각을 했는지, 코드 버그인지 분류.
- 코드를 고친다.
- 로컬에서 재현·검증한다 → 단순 unit test로는 부족하고, 진짜 webhook 경로로 LLM까지 태워야 한다.
- 같은 클래스의 버그가 다른 곳에서도 일어나고 있는지 과거 trace를 스캔한다.
이걸 사건마다 사람 머리로 다시 짜다 보면, 어느 단계는 빠뜨리고, 어느 단계는 confirmation bias에 빠지고, 어느 단계는 prod 환경변수로 로컬 서버를 띄우는 위험천만한 짓을 하게 된다. 매번 같은 함정에 같은 사람이 빠진다.
그래서 이 절차 자체를 Claude Code의 skill로 만들었다. 이 글은 그 스킬의 설계 결정과 거기서 배운 것들에 대한 이야기다.
스킬이 하는 일
호출 형태는 단순하다. 상담사 제보 원문(고객·봇 발화 조각이 들어 있으면 충분)을 붙여 넣으면, Claude Code가 다음을 자동으로 한다.
- 사건 폴더(
<incident_id>=YYYY-MM-DD_<slug>)를 만든다. state.yaml에 incident 메타를 기록하고, 4단계 폴더(01_intake/02_investigate/03_fix/04_verify)를 스캐폴딩한다.- dev 환경변수를 자동으로 받아온다 (사용자에게 묻지 않는다).
- LLM 관찰 플랫폼에서 발화 조각을 씨앗으로 trace를 역추출하고, tool 응답·LLM 응답을 대조해 근본 원인 가설을 세운다.
- 코드를 수정하고 로컬에서 webhook 재생(replay)으로 재현·검증한다.
- 마지막에 PR을 올리고 incident 상태를
closed로 닫는다.
겉보기엔 평범한 디버깅 워크플로우지만, 안에 들어 있는 설계 결정 몇 개가 이 스킬을 쓸만하게 만든다.
설계 결정 1 — state.yaml은 곧 DB row
폴더 구조는 의도적으로 미래의 DB 스키마를 닮게 만들었다.
<incident_id>/
state.yaml # incidents 테이블 row
01_intake/report.md # incident_artifacts 테이블 row
02_investigate/{trace, log, findings}.md
03_fix/{plan, changes}.md
04_verify/{result, audit, pr_body}.md
04_verify/payloads/turn1.json # webhook replay payload
각 .md는 YAML frontmatter(DB 컬럼에 대응) + 본문(자유 서술). state.yaml의 stages.<N>.artifacts[]가 그 stage에 속하는 artifact 경로 목록을 담는다.
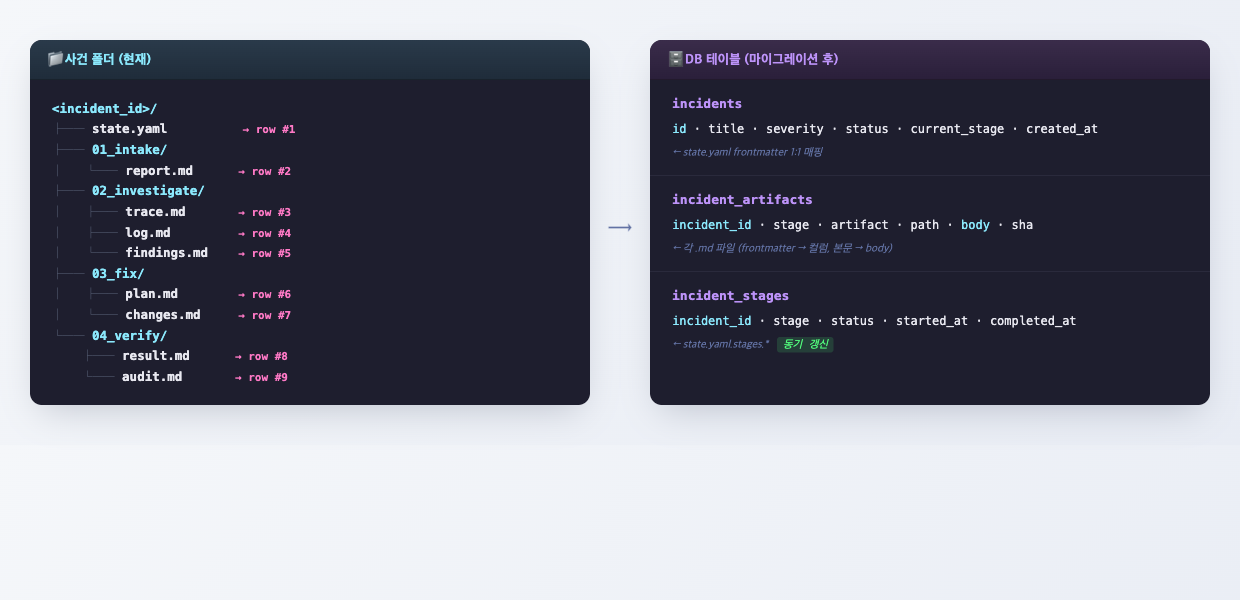
이렇게 한 이유는 두 가지다.
(1) 세션 중단 시 복원이 가능하다. Claude Code 세션이 중간에 끊겨도, 다음 세션에서 같은 incident_id로 스킬을 다시 호출하면 state.yaml의 current_stage · next_action으로부터 정확히 다음 수행 지점을 이어받을 수 있다. 이걸 위해 스킬은 artifact 작성 직후 같은 turn 안에서 state.yaml을 함께 갱신하도록 강제한다. "나중에 한꺼번에 업데이트"는 금지.
(2) 사건이 누적되면 DB로 옮긴다. 사건이 충분히 쌓이면 incidents, incident_stages, incident_artifacts 테이블로 마이그레이션할 계획. 그때 마크다운 본문은 body 컬럼에 그대로 들어가고, frontmatter는 컬럼 매핑된다. 위 도식이 그 매핑 골격이다.
설계 결정 2 — "묻지 말고 진행하라"가 기본
스킬이 사용자에게 가장 자주 보내는 잘못된 메시지는 다음과 같은 것들이었다.
".env를 먼저 받아와 주세요" "환경 파일 확보 후 진행하겠습니다" "PR 올릴까요?"
이런 대기는 거의 항상 잘못된 보수주의다. SKILL.md에는 명시적으로 자동 진행 규약을 박아넣었다.
| 자동 진행 OK | 사용자 확인 필요 |
|---|---|
| worktree 내 모든 파일 편집 (코드·프롬프트·테스트·artifact) | PR merge / release |
| dev 환경변수 다운로드 | prod 서버 재기동·prod 배포 |
| 로컬 서버 기동 (dev env 기준) | 외부로 메시지 발송 (Slack / 이슈 코멘트) |
git push + gh pr create (Stage 4 종료 단계) | 코드 블록 대량 삭제 (복구 고비용) |
특히 프롬프트 파일 수정에 대한 보수주의가 흔한 함정이다. production에서 쓰이는 프롬프트라도, worktree 안에서 편집하는 건 production에 영향이 없다 — merge·deploy 되기 전까지는 로컬 파일 변경일 뿐. "production 프롬프트이니 확인 필요"는 잘못된 판단이라고 SKILL.md에 못박았다.
설계 결정 3 — dev 환경 강제 + 합성 user ID 강제
로컬 검증에서 가장 위험한 시나리오는 두 가지다.
- prod 토큰으로 로컬 서버를 띄움 → 실고객에게 잘못된 메시지가 발송될 수 있음.
- 실고객 session id를 webhook payload의 user 필드에 그대로 복붙함 → replay trace가 실고객 trace와 섞여 분석이 오염되고, 만에 하나 push 차단이 풀리면 실고객에게 메시지가 발송됨.
이 두 가지를 막기 위해 webhook 재생용 helper 스크립트를 따로 만들었다. 동작은 의사코드로 표현하면 이런 형태다.
function replay(payload_file, user_id):
if not user_id.startswith("debug-"):
fail "실고객 session id 사용 절대 금지"
if payload_file.user != user_id:
fail "payload.user와 --user 불일치"
POST /webhook ← payload_file
wait for new conversation log line
extract ai_response
assert expected_keyword in ai_response
assert forbidden_keyword not in ai_response
--user가 debug-로 시작하지 않으면 거부, payload의 user 필드와 --user가 다르면 거부. 이 두 가드 덕분에 "이 trace 그대로 재현하려고 user id 복붙" 같은 무심코 한 행동이 즉시 실패한다.
서버 기동 쪽에는 이중 차단을 걸었다.
START local server WITH:
SEND_TOKEN = DISABLED # 외부 메시지 API 인증 무효화
ALERT_WEBHOOK = (empty) # 에러 알림 차단
토큰이 무효화돼 있고 user가 합성 ID라서, 만약 push 차단이 풀려도 외부 API가 "잘못된 user 값"으로 거절한다. 실측에서 확인된 이중 안전장치다.

이 다층 방어의 핵심은 각 layer가 서로 독립적으로 동작한다는 것이다. 한 layer를 깜박하고 우회해도 다음 layer가 잡는다. 안전장치는 곱셈이지 덧셈이 아니다.
설계 결정 4 — 4-Audit: 한 사건의 종료 ≠ 클래스의 종료
스킬에서 가장 중요하게 만든 단계가 마지막의 4-Audit (소급 감사) 게이트다.
원칙은 단순하다.
한 incident만 고치고 끝내면, 같은 클래스의 다른 필드에서 똑같은 버그가 별도 incident로 다시 터진다.
그래서 Stage 2의 findings.md에는 "확산 가설" 섹션을 의무화했다. 이번 버그의 추상 클래스 이름을 붙이고 (예: "tool 응답을 사용자 발화가 덮어쓰는 sycophancy", "N-off-by-one 계산 오류", "nullable 필드 미체크 환각"), 같은 클래스가 발생 가능한 인접 지점 후보 3개 이상을 나열하고, 각 후보에 대해 "이미 막혀 있는 이유" 또는 "가드가 필요한 이유"를 코드/프롬프트 grep 결과를 인용해 명시한다.
Stage 3의 plan.md 첫 섹션은 그 가설을 근거로 **수정 범위(넓음/좁음)**를 명시적으로 선택한다. 기본값은 넓은 수정. 좁게 가려면 사유를 적어야 한다.
Stage 4 끝에는 PR을 올리기 전에 소급 스캔 게이트가 있다. 최근 한두 달 production trace를 패턴 매칭해서, 같은 버그 클래스가 과거에 몇 건 발생했는지 센다.

| audit 결과 | 행동 |
|---|---|
| 0건 | audit.md에 "클린" 명시 후 PR 진입 |
| 1건 이상 + 본 수정으로 커버됨 | PR body에 "과거 N건 소급 영향" 표 포함 (CS 재연락 대상 리스트) |
| 1건 이상 + 본 수정으로 커버 못함 | Stage 3로 되돌아가 plan 확장. 좁은 수정 → 넓은 수정. 처음부터 다시 검증 |
소급 히트가 있으면서 fix가 그 케이스를 못 막는 상태로 PR을 올리면, 사건은 닫힌 것처럼 보이지만 production은 여전히 샌다. 이걸 막는 게 4-Audit의 의무화 이유다.
의도적으로 빼놓은 것들
스킬을 좋게 만드는 만큼 중요한 게 "빼놓는" 결정이다.
- LLM trace 조회·로그 쿼리 같은 횡단 레시피는 별도 스킬로 분리. 본 스킬은 "이 봇 서비스의 trace 이름은 무엇인가, 어느 region을 쓰는가" 같은 봇 서비스 고유 상수만 정의한다. 쿼리 도구 사용법은 위임.
- 구체 incident 사례는 SKILL.md에 포함하지 않는다. 스킬을 쓰는 미래의 Claude Code 에이전트에게 특정 버그의 정답이 공짜로 전달되면 confirmation bias·test contamination의 원인이 된다. 과거 사건의 교훈은 사건 폴더 아래에 incident별로 남고, 새로 들어온 사건은 그 자체로 처음 보는 것처럼 다뤄지게 했다.
- PII 보호. 사건 폴더는
.gitignore에 추가. 고객 이름·연락처·주문번호가 intake/investigate artifact 안에 그대로 들어가기 때문. 외부 공유는 사건 ID와 요약만.
무엇이 달라졌나
스킬을 쓰기 전에는 사건 한 건 디버깅에 평균 반나절이 들었다. 절차를 머리로 짜맞추고, 환경변수를 어디서 받아와야 하는지 매번 다시 찾고, 검증을 unit test로 어설프게 끝내고, 소급 스캔은 잊어버리고. 스킬을 만든 후에는 사건 한 건이 짧으면 한 시간, 길어도 두세 시간 안에 닫힌다. 더 중요한 건 "같은 함정에 같은 사람이 다시 빠지는" 일이 줄었다는 것.
스킬을 만들면서 가장 크게 배운 건, 이런 운영 워크플로우 스킬은 자동화 도구가 아니라 체크리스트의 진화형이라는 점이다. Claude Code가 단계마다 "다음에 뭘 할지 / 무엇을 잊지 말지 / 어떤 함정을 피할지"를 컨텍스트에 강제로 가지고 있게 만드는 도구. 모델은 충분히 똑똑하지만, "이 단계에서 사용자에게 묻지 말 것", "이 검증 없이는 PR 올리지 말 것" 같은 운영 제약은 누군가가 명시적으로 박아넣어 줘야 한다.
다음에 같은 종류의 운영 스킬을 또 만든다면, 시작은 항상 반복되는 함정의 목록에서 시작할 것 같다. 워크플로우 자체보다 그 워크플로우가 무엇을 막아주는지가 스킬의 존재 이유니까.